GaMMA
GaMMA
GaMMA
GaMMA
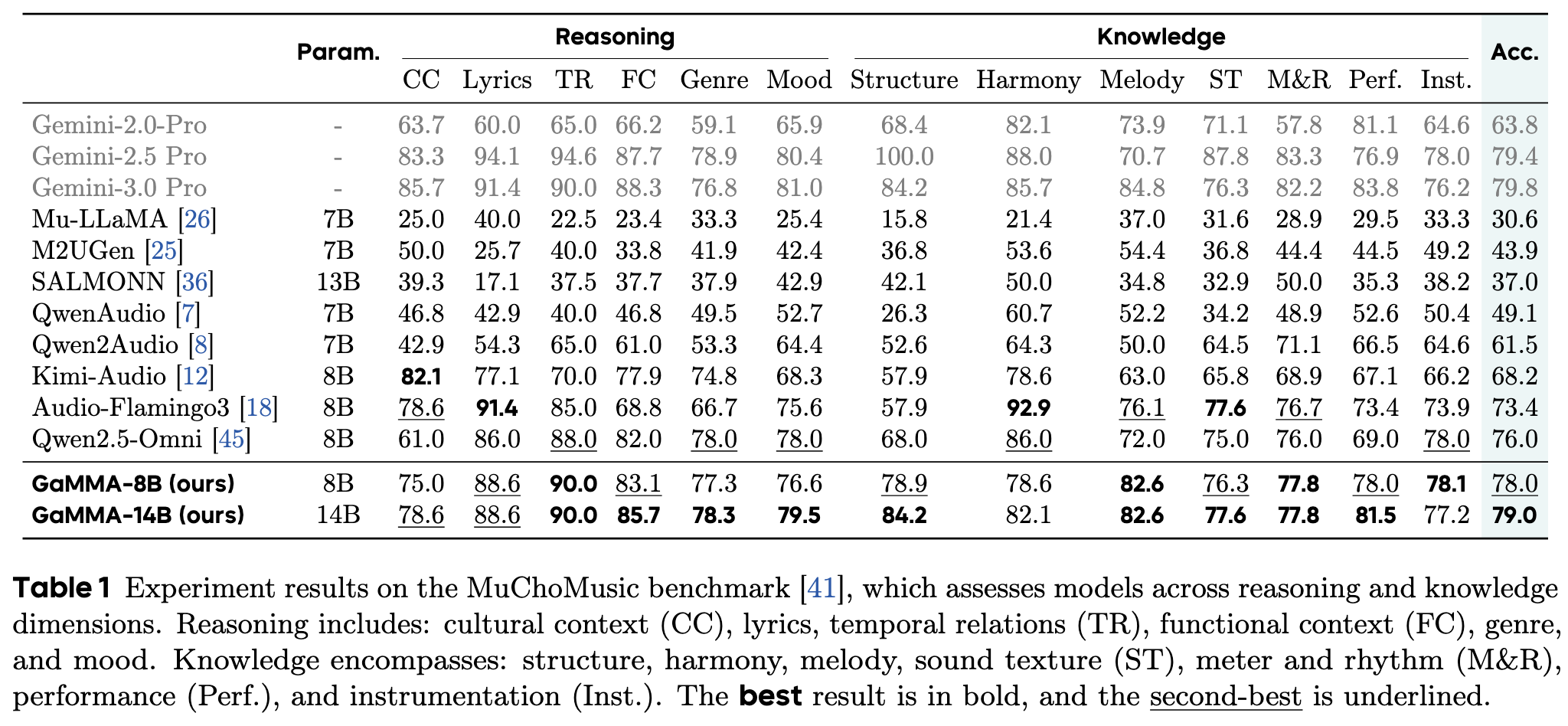
Introducing GaMMA, a large multimodal model designed to jointly handle both global music understanding and temporal music reasoning within a unified parameter space. Built on a streamlined encoder-decoder paradigm, GaMMA combines language modeling with dual audio experts and a gated fusion mechanism to model both non-temporal musical semantics and time-dependent musical structure, while a progressive training pipeline based on pretraining, supervised fine-tuning, and reinforcement learning further strengthens instruction-following, full-song understanding, and temporal reasoning.
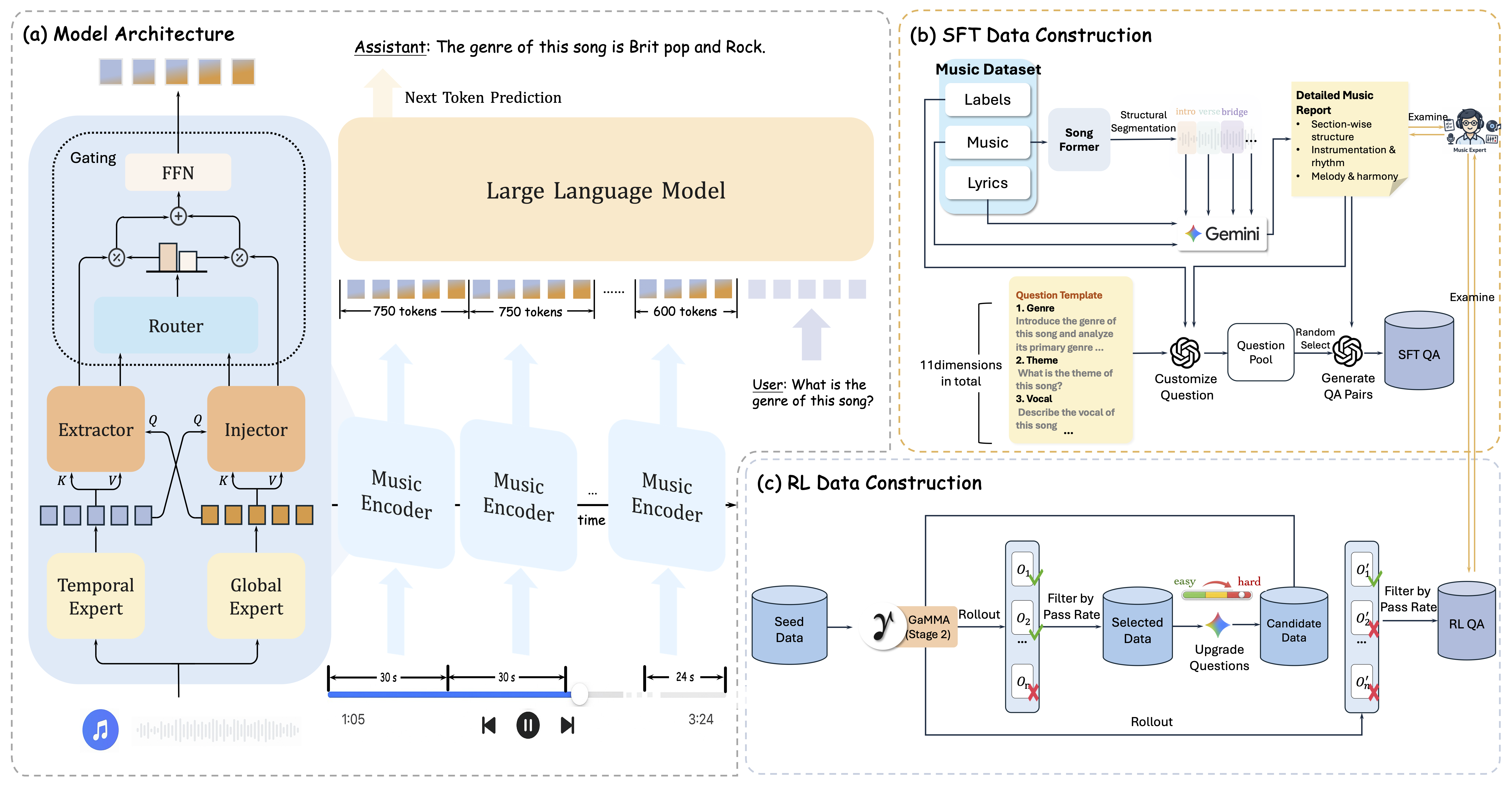
GaMMA jointly models temporal and non-temporal music understanding with dual Whisper-based audio experts, where a temporal expert captures time-dependent structure and a global expert models holistic musical semantics, and their representations are fused through a gated extractor-injector design for full-song reasoning. On the data side, the pipeline first constructs SFT data by segmenting songs into fine-grained musical structure, combining aligned music and lyrics to produce expert-verified music reports and multi-turn QA pairs across diverse musical dimensions, and then builds RL data by selecting moderately difficult questions through rollout-based pass-rate filtering and upgrading them into harder but answer-consistent candidates.
We provide a demos with audible music clips here to provide a more intuitive presentation of qualitative results related to the main paper, further demonstrating GaMMA's strong capabilities in music understanding. Note that for each music clip, only the audio is used as input; the model has no access to the song title or the artist information. Demos are organized as follows:
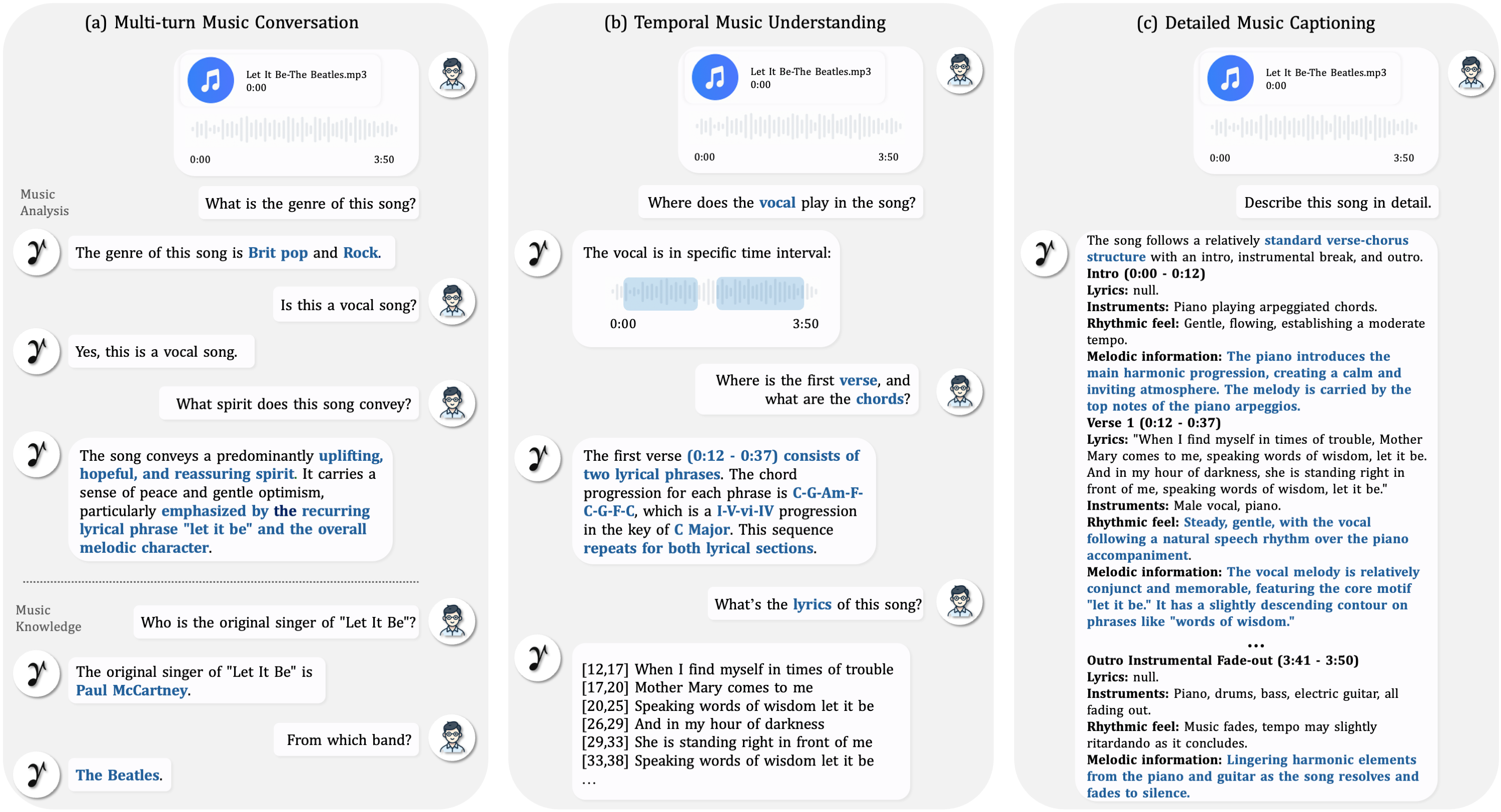
GaMMA supports multi-turn conversations grounded in full-song audio, answering follow-up questions about musical highlights, emotional arcs, structure, and creative interpretation while keeping context across turns.
GaMMA handles music understanding and discussion in multiple languages, supporting questions about meaning, lyrics, vocal attributes, and time-specific musical events across Chinese, Japanese, Spanish, and more.
GaMMA provides general text-only interaction for everyday dialogue, knowledge questions, and lightweight reasoning tasks even when no music input is provided.
GaMMA generates detailed music reports with fine-grained descriptions of structure, lyrics, instrumentation, harmony, and progression, providing long-form analysis grounded in the full audio content.
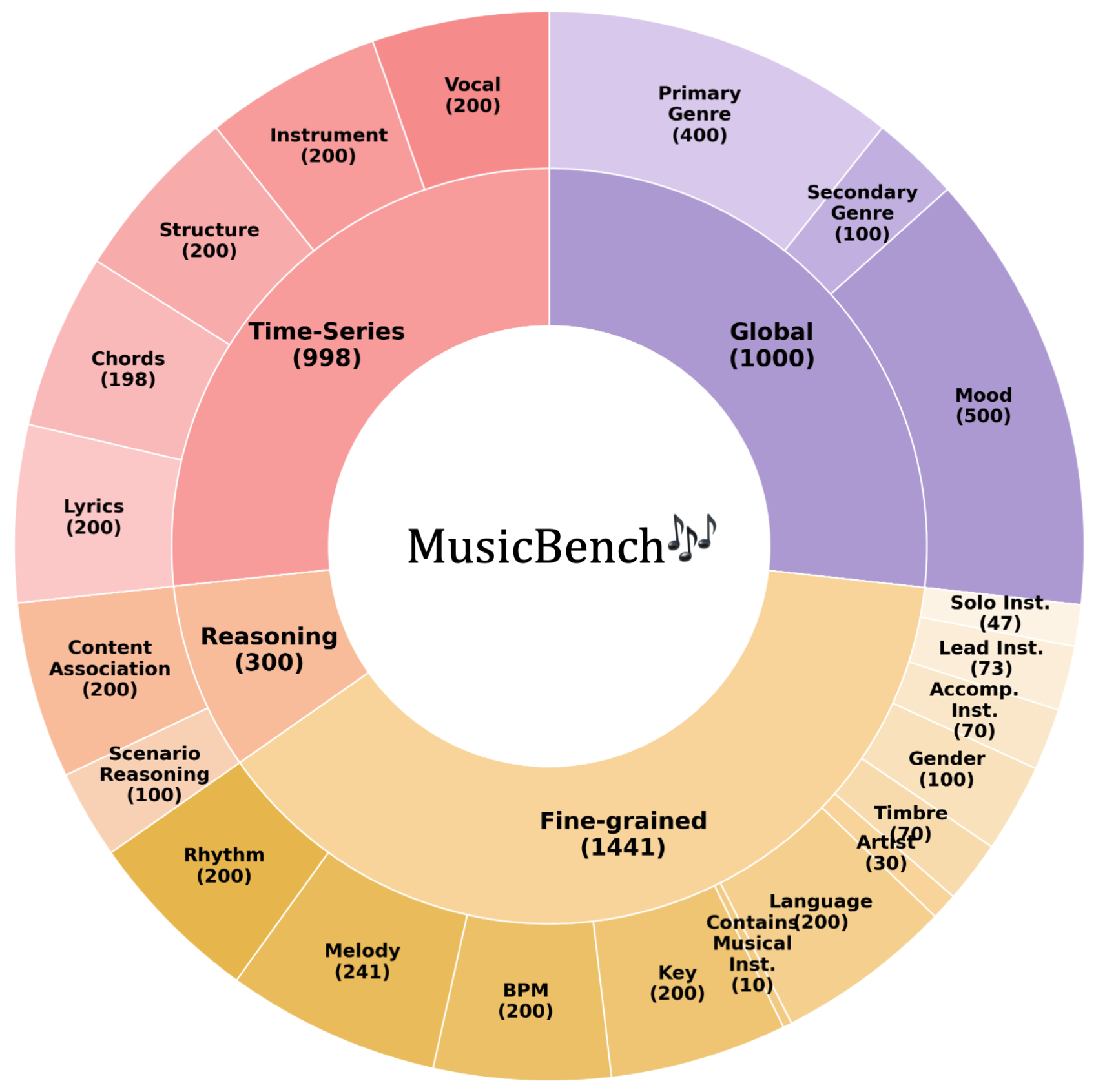
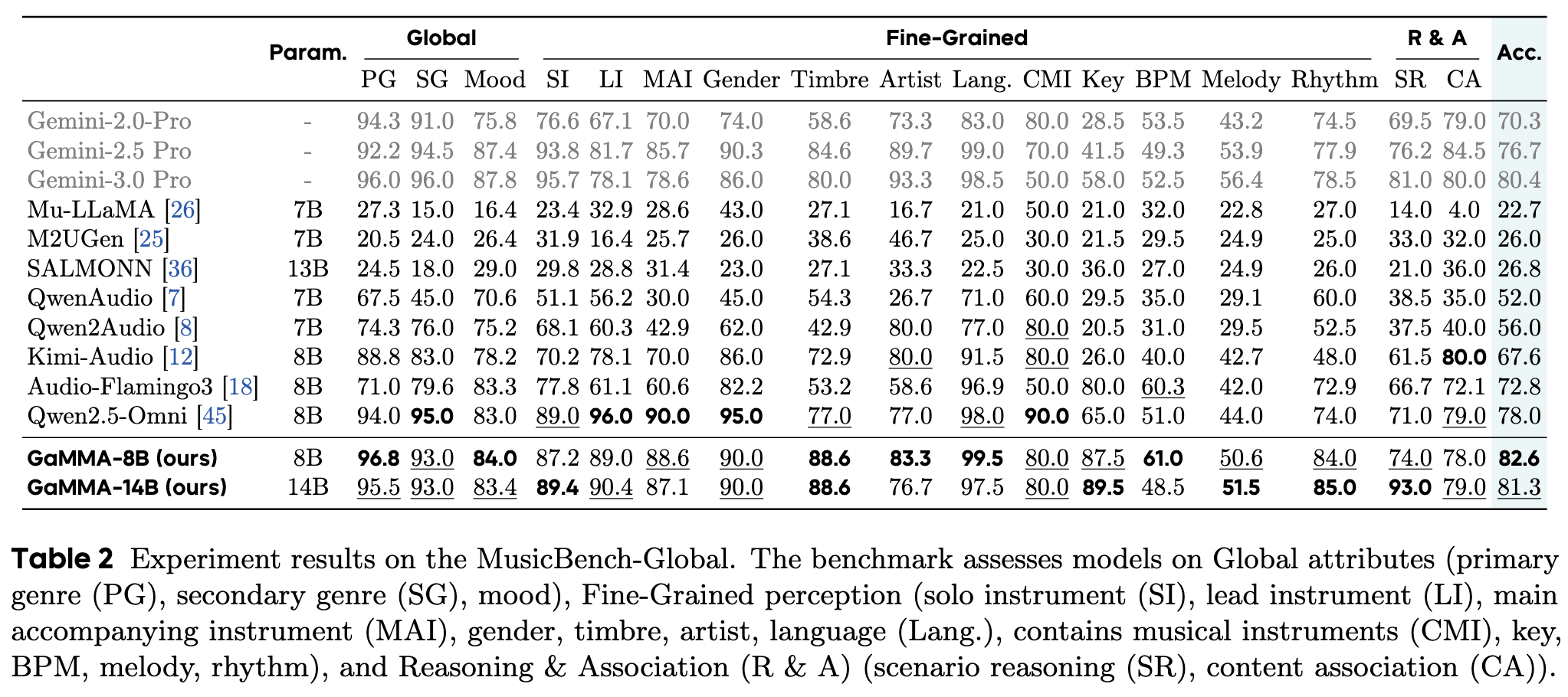
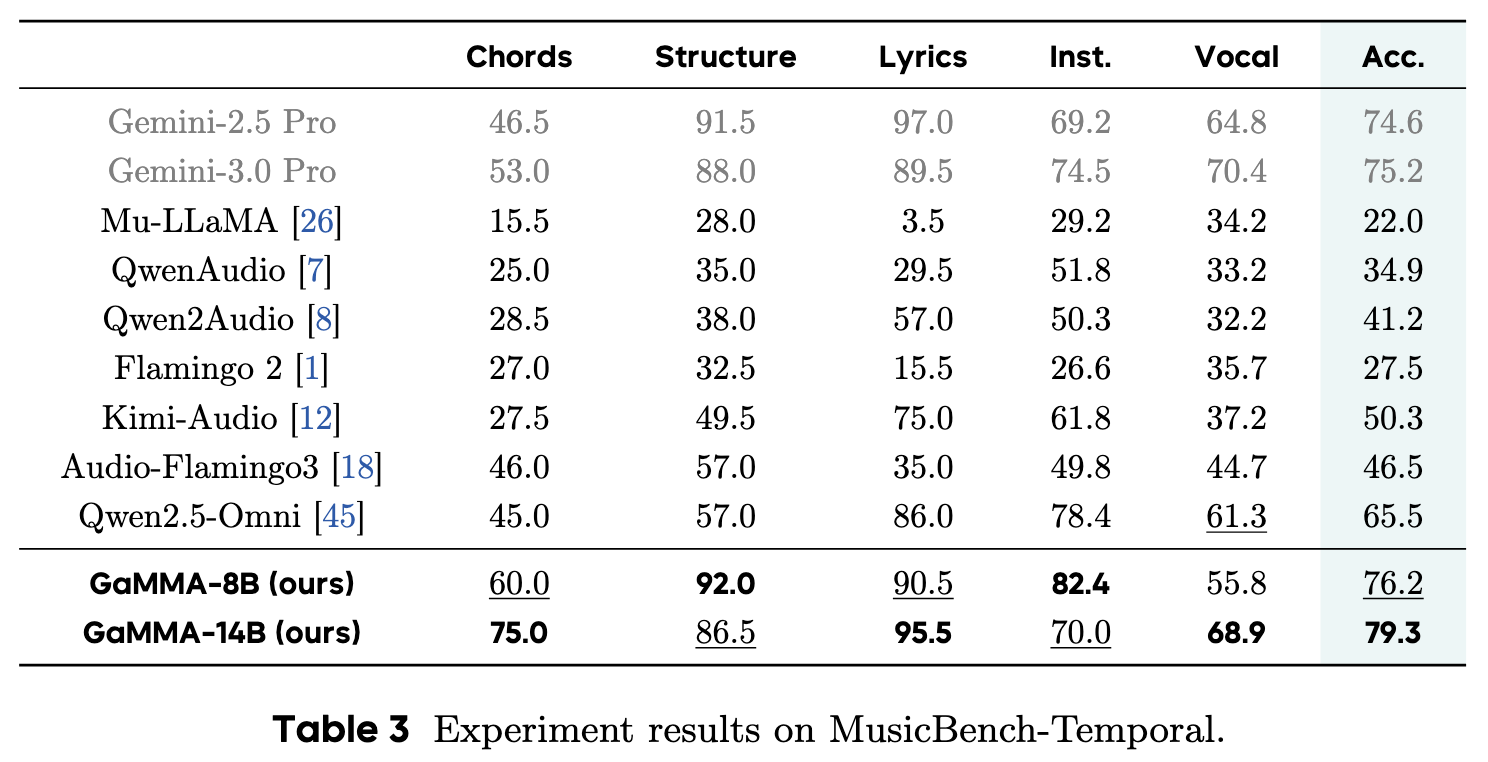
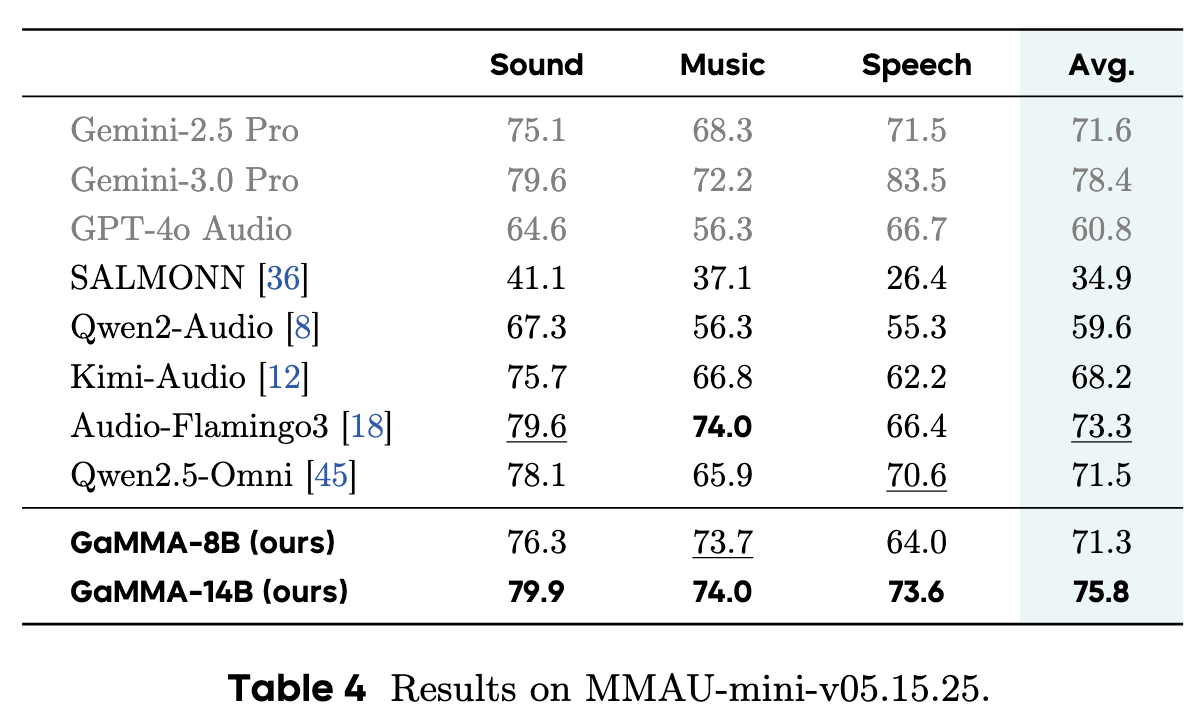
MusicBench is a comprehensive benchmark for music-language models with 3,739 human-curated multiple-choice questions covering both temporal and non-temporal understanding. It is organized into two primary subsets, MusicBench-Global with 2,741 questions on global and fine-grained musical attributes such as genre, mood, instrumentation, key, BPM, melody, rhythm, and association, and MusicBench-Temporal with 998 questions focused on reasoning over time, including vocals, instruments, structure, chords, and lyrics, providing a structured evaluation of broad music understanding and temporal reasoning.
@misc{you2026gamma,
title = {GaMMA: Towards Joint Global-Temporal Music Understanding in Large Multimodal Models},
author = {You, Zuyao and Yu, Zhesong and Liu, Mingyu and Zhu, Bilei and Wan, Yuan and Wu, Zuxuan},
journal = {arXiv},
year = {2026}
}